Private LLMs vs. RAG Systems: Why a Hybrid LLM May Be the Best Path for Law Firms
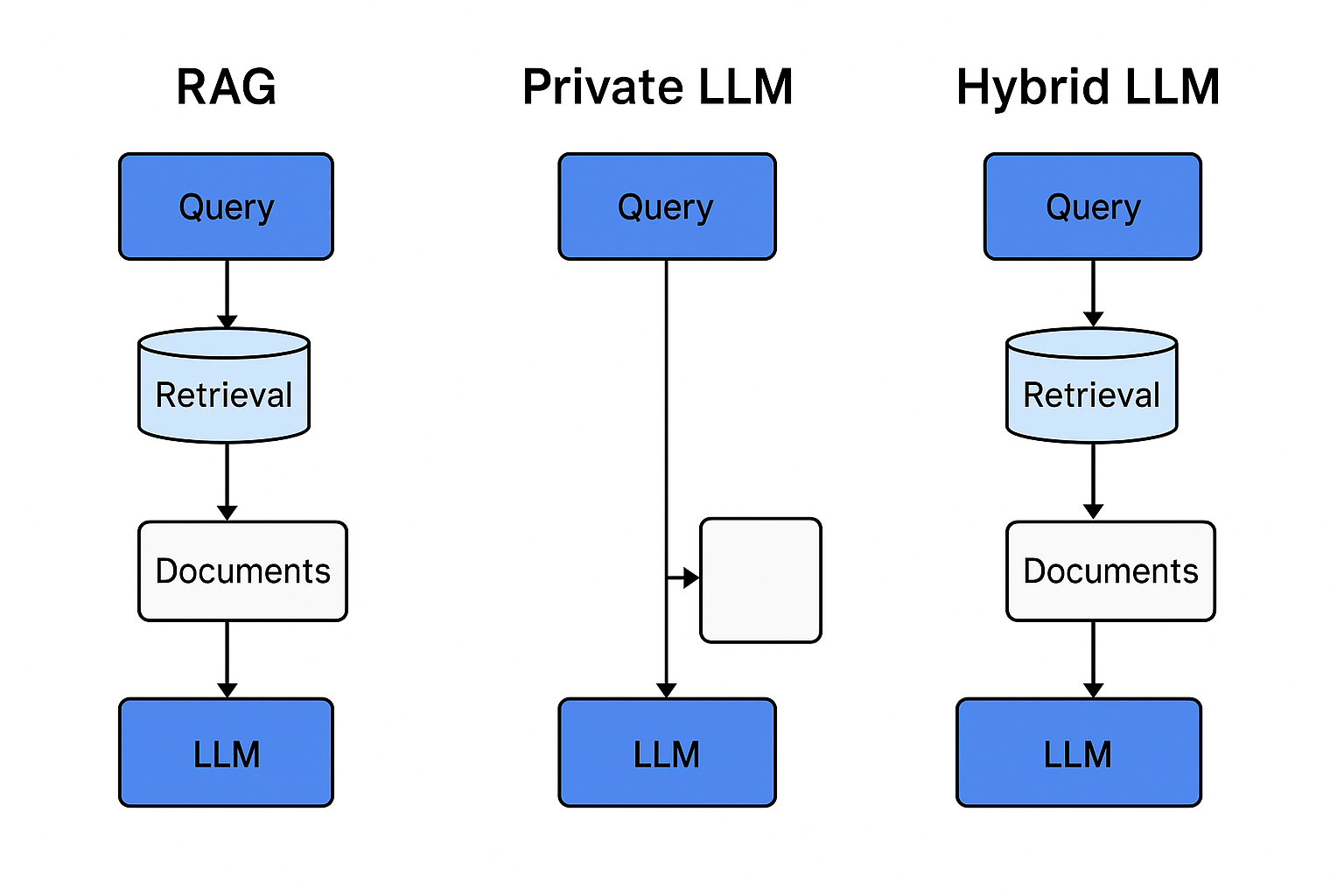
Law firms evaluating AI face a choice between Private LLMs—high-control but costly and static—and RAG systems, which are cheaper, faster, and always up to date. Each has strengths and drawbacks, but the most effective strategy is often a hybrid: combining the reasoning power and style of private LLMs with the freshness and accuracy of RAG retrieval.

Artificial intelligence is quickly reshaping the way law firms handle research, drafting, and client communication.
But when it comes to choosing an AI strategy, most law firms find themselves staring at two competing models:
- Private Large Language Models (LLMs) private legal LLMs are trained and hosted entirely in-house or on a server (e.g. AWS or Azure) you control.
- Retrieval-Augmented Generation (RAG) systems, which combine powerful general-purpose LLMs with external knowledge retrieval from firm documents.
Both options come with clear advantages—and equally clear tradeoffs.
The choice isn’t as simple as “one or the other.” In fact, a hybrid approach may offer the balance law firms need to stay secure, accurate, and efficient.
Private LLMs: Control at a Cost
Private LLMs are custom-trained AI models built and operated behind a law firm’s firewall.
Advantages:
- Maximum control over data, privacy, compliance and training.
- Can be fine-tuned on highly specialized legal domains, documents, contracts and case law.
- Reduces reliance on third-party vendors.
Drawbacks:
- Very expensive to build and maintain. For instance, a single legal custom-trained LLM can cost north of $1M just to provide the custom training.
- Requires significant technical talent (often outside the scope of most firms).
- Knowledge is “frozen” in time—the model won’t know about new cases or regulations unless retrained.
For large firms with big budgets and IT departments, private LLMs may be viable. But for most, the financial and operational burden is a dealbreaker.
| Decision Factor | Private LLMs | RAG | Hybrid (RAG + LLM) |
|---|---|---|---|
| Implementation timeline | Months—infra + training | Days–weeks with vendor stack | Weeks (start RAG, layer fine-tunes) |
| Upfront cost | High (compute, team, tooling) | Low (subscription/usage) | Moderate (targeted fine-tunes + RAG) |
| Ongoing cost | Maintenance + periodic retraining | Indexing + API usage | Selective fine-tunes + retrieval ops |
| Expertise required | AI/ML team + MLOps | Search/RAG vendor + light dev | RAG skills + targeted LLM tuning |
| Knowledge freshness | Static; retraining needed | Real-time via new docs | Real-time + curated core model |
| Answer accuracy / grounding | Can drift if training data is old | Grounded in retrieved sources; retrieval quality matters | Best: retrieval + model refinement/validation |
| Security & control | Max control (in-house) | Strong with proper vendor + isolation | Keep sensitive cores private; retrieve the rest |
| Compliance fit | Custom controls; heavy lift | Vendor attestations + firm policies | Private controls + vendor attestations |
| Latency & scale | Fast after deployed; costly to scale | Scales with vendor infra | RAG scales; private bits sized to need |
| Vendor lock-in | Low (but you own the burden) | Medium (APIs/indexes) | Low–Med (modular: swap parts) |
| Typical use cases | Firm-specific tone, templates, niche doctrine | Research, KM, clause search, precedent recall | High-stakes drafting with citations + style |
| Key risks | Cost/obsolescence | Retrieval misses → hallucinations | Mitigates both via checks & grounding |
| When it wins | Huge IT budget + strict data residency | Need speed, freshness, lower cost | Balanced control, accuracy, ROI |
Tip: Start with RAG for fast wins; add a small private model (fine-tuned on firm style/precedent) and a validation step (e.g., cite-checking) to reach hybrid reliability.
RAG Systems: Fast, Flexible, and Up-to-Date
RAG systems work differently. Instead of storing all knowledge in the model itself, they retrieve documents on demand (e.g., statutes, case files, contracts) and feed that context into the LLM before it generates an answer.
Advantages:
- Easy to deploy with off-the-shelf vendor tools.
- Keeps outputs current, since new documents are instantly searchable.
- Lower upfront costs—usually pay-as-you-go or subscription-based.
- Access to cutting-edge LLMs without needing to train your own.
Drawbacks:
- Retrieval quality depends on the indexing system. If relevant documents aren’t retrieved, the model may hallucinate.
- Less control compared to fully private setups.
- Still requires governance around data security and vendor compliance.
For most firms, RAG systems strike a good balance of usability, affordability, and effectiveness—especially for legal research and internal knowledge management.
Why a Hybrid Approach Makes Sense
The reality is that neither option is perfect in isolation.
A hybrid LLM strategy—where a base LLM is combined with RAG pipelines—can mitigate the biggest weaknesses of each.
- Accuracy + Freshness: The LLM provides reasoning ability and style, while RAG ensures answers are grounded in the most recent and relevant firm data.
- Security + Flexibility: Core legal knowledge (e.g., firm-specific precedents) can be locked inside a private model, while less sensitive updates can be retrieved dynamically.
- Cost Balance: Instead of training a massive model on everything, firms can maintain a smaller specialized LLM and lean on RAG for the rest.
Emerging systems already show this in practice. Some use dual retrieval (semantic search + knowledge graphs), while others run LLM-based “checkers” to validate retrieved documents before generating an answer.
These methods reduce hallucination and improve trustworthiness—critical in high-stakes legal environments.
Strategic Takeaways for Law Firms
- Pure Private LLMs = deep control, but high cost and outdated quickly.
- Pure RAG Systems = lower cost, real-time knowledge, but retrieval risks.
- Hybrid Models = balanced, practical, and future-proof.
The most pragmatic path for most firms is to start with RAG, prove value quickly, and then layer in private model components for areas requiring tighter control.
The Case for Hybrid LLMs for Law Firms
Law firms don’t need to choose between being locked into expensive private LLMs or relying entirely on vendor-driven RAG systems.
A hybrid LLM model—combining the reasoning power of LLMs with the freshness of retrieval—offers the best of both worlds.
For legal teams, this means smarter research, safer outputs, and better ROI—without the rigidity or risk of going all in on one approach.
Ready to perform contract review with your own private LLM? Contact us today.



Bringing AI in-house, the right way.
Talk through your private or on-prem LLM deployment with an expert who has shipped them in regulated environments.
Private AI, in your inbox.
Occasional, high-signal notes on enterprise LLM deployment, security, and model strategy. No spam.